2)データの保存
(1)オリジナルファイル(表計算ソフト独自の形式で書式などを含んでいる)の保存
適当な名前をつけて保存。
たとえばmihondata.xls
(2)テキスト形式での保存
オリジナルファイルのままでは読み込めないので、Rで読み込めるような”(タブ区切り)テキスト形式”で保存しなおし。
エクセルの場合
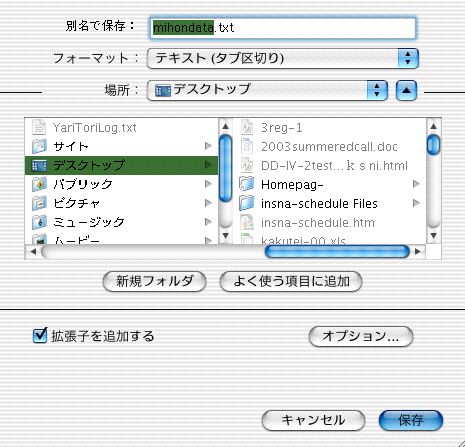
ファイル->別名で保存 ->フォーマット(ファイルの種類)->テキスト(タブ区切り)
として、適当な名前で保存。
例えば mihondata.txt
このとき、桁数が大きい数字で , で区切られていると、読み込んだときに文字列として扱われるので ,表示はしない。