
5)��A�f�f
�@���^��A���͂́A���L�̏�����O��Ƃ��Ă���B����炪�������Ă��邩���`�F�b�N���邱�Ƃ��K�v�B
�@�\���I���͂������Ȃ��Ă����A�����̖��͔�������B
�}�\�@���^�̉�A���͂ł̉���
|
���� |
�Ǐ�/�����ƑΉ��� | ||
| ���`�ɂ��� |
�E���^�� �@�@������ϐ��Ɛ����ϐ��ɂ͐��`�̊W������B |
||
| �덷���Âɂ��� |
�E�덷���̕��ϒl��0 �@E(��i)=0 �E�덷����(����0�A���U��2��)���K���z�ɏ]���B �@��i�`N(0,��2) �E�덷���̕��U�̓�2�̈��l�B �@Var(��i)=��2 �E�덷���͓Ɨ��ɕ��z�B �@cov(��i,��i')=0 �@ �@���ɂ��Ă�t����A���f���S�̂�F����́A�덷�������K���z���邱�Ƃ�O��Ƃ��Ă���B���̉��肪��������Ă��Ȃ��ꍇ�A���茋�ʂ��M���ł��Ȃ��Ȃ�B |
�E�c���̃q�X�g�O���� �@���K���z���Ă��邩�H �EQ-Q�v���b�g �@�c�������K���z����Ɖ��肵���Ƃ��̗��_�I�ȕ��z�ƌ����̕��z�Ƃ��r�B �E�͂���l�̌��o �@Cook�̋��� �E�\���l-�c���v���b�g �@�\���l�Ǝc���Ƃ̊ԂɌn���I�ȊW���Ȃ����H |
�E�͂���l �@���̓~�X �@�ϐ��ϊ� �@���͂��珜�O�������́A�͂���l�_�~�[ �E���U�s�ψ� �@�ϐ��ϊ� �@�@�����ϐ��̒lj� �E�n�� �@���n�͂̏ꍇ�A�덷���O���̌덷�Ƒ��ւ��Ă��邱�Ƃ�����B �E�s�K�ȕ��z �@�E��̎R������ꍇ�́A�O���[�v�ʂɐ��肷�邩�A�_�~�[�ϐ�������B �@�E�ϐ��ϊ�����B �E�����ϐ��̒lj� |
| �����ϐ��Ԃɂ��� |
�E�����ϐ��̓����_���ϐ��ł͂Ȃ��A���O�ɑI���������͌Œ肳��Ă���B �E�����ϐ��͌덷�Ȃ����肳��Ă���B �E�����ϐ��͐��^�Ɨ��B �@���茋�ʂ��s����ɂȂ�B�����I�ɂ݂Ă��������������ł�B �@��@�n��ʏ��Ɣ̔��z��l���Ɛ��ѐ��Ő�������ƁA�Ⴆ�ΐ��т̕������}�C�i�X�ɂȂ�B |
�E�����Ȃ���̏����͖�������邪�A�����łȂ��ꍇ�͖�������Ă��邱�Ƃ̕����������B���̂悤�ȏꍇ�ɂ́A���ʐ��ɂ��Č��_�Â��邱�Ƃ͋ɂ߂č���B �@��@�l�̎q���̏o�������A�����̂Ƃ�@�̐��Ő������ėL�ӂł������Ƃ��Ă��A�����̂Ƃ�A���q�����^��ł���Ƃ͂����Ȃ��B �E�덷�̕]���͍���B �@���Ȃ��Ƃ��A���肵�����T�O�ɂӂ��킵���ϐ���I�����邱�ƁB �@��@�s�s����m�\�Ƃ����T�O�ɂӂ��킵���ϐ��͉����H �E�����ϐ��Ԃł̃v���b�g �E�����ϐ��Ԃ̑��W���̎Z�o �EVIF�̎Z�o |
�E�����ϐ��̌덷�����l���������́i�����U�\�����́j�Ȃǂ����邪�A���̎��Ƃł͊����B �E���ւ������ϐ��Q������ꍇ�A����炩��A�ǂꂩ��݂̂�p����B �E���ւ������ϐ��Q���Ȃ�炩�̕��@�ŏW��B �@��@�K���ȕ��@�Ŏw�����쐬����B �@���q���́A�听�����͂Ȃǂ�K�p����B |
| �ϑ��ɂ��� | ���ׂẴT���v���͓����悤�ɐM���ł���B | �E�]���͍���B |
�o���jHair, Jr., Joseph, Rolph E. Anderson, Ronald L. Tatham, and William C. Black,(1995),Multivariate Data Analysis with Readings 4th ed.,Prentice Hall: NJ, p.112
|
#��قǂ̃��f��2�ɂ��Ďc���v���b�g���݂�B�܂��͉�A���́B result2<-lm(nofdl~nrelease+tpcgames,ossdata) summary(result2) #Coefficients: # Estimate Std. Error t value Pr(>|t|) #(Intercept) 3058.4 2402.9 1.273 0.20631 #nrelease 481.2 149.0 3.229 0.00172 ** #tpcgames 14158.7 4995.9 2.834 0.00565 ** #--- #Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 #Residual standard error: 17230 on 92 degrees of freedom #Multiple R-Squared: 0.175, Adjusted R-squared: 0.1571 #F-statistic: 9.758 on 2 and 92 DF, p-value: 0.0001435 #�����result2�̒��ɉ��L�̕ϐ����i�[�����B names(result2) # [1] "coefficients" "residuals" "effects" "rank" # [5] "fitted.values" "assign" "qr" "df.residual" # [9] "xlevels" "call" "terms" "model" plot(result2) #�Ƃ���Ǝ����ŗL�p�ȃv���b�g�����Ă����B #���肳�ꂽ�]���ϐ��Ǝc���Ƃ̃v���b�g #����`���A�͂���l�A���U�s�ψ�Ȃǂ̃`�F�b�N plot(result2$fitted,result2$residual) 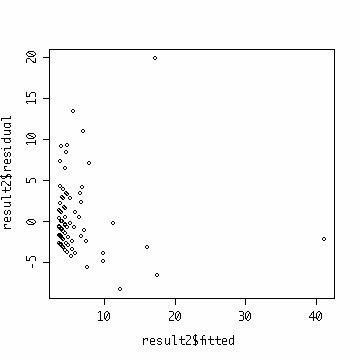 |
�}�\ �@�c���Ɨ\���l�Ƃ̃v���b�g
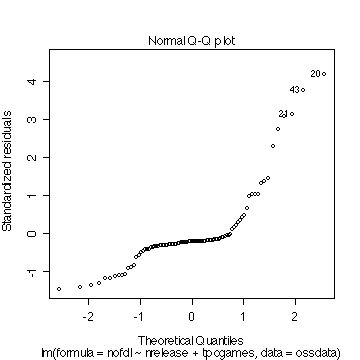
�E�S���ʐ��v���b�g(Q-Q�v���b�g)
�@�c�������K���z����ꍇ�ɂ͒�����ɕ��ԁB
�}�\ �@�S���ʐ��v���b�g(Q-Q�v���b�g)
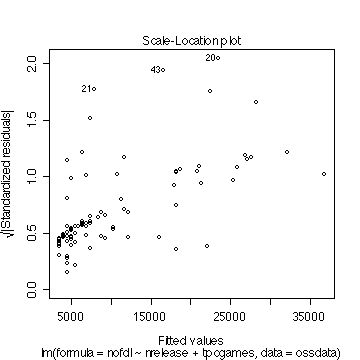
�E�W���������c���Ɨ\���l�Ƃ̃v���b�g�B
�@��O�̂��̂Ɠ����ǂݕ��B�������A�c�����W��������Ă���̂ŁA�W�����c���̐�Βl��2�����傫���ꍇ�A�͂���loutlier�ƍl����A�Ƃ������c�_���\�B
�}�\ �@�W�������ꂽ�c���Ɨ\���l�Ƃ̃v���b�g
|
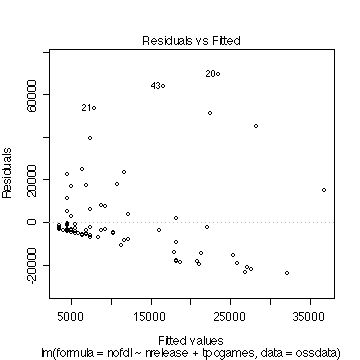
#20�Ԗڂ̃T���v���̃f�[�^���݂�ɂ͎��̂悤�Ɏw�肷��悢�B ossdata[20,] #�������c����\���l���݂Ă݂� result2$residuals[20] result2$fitted.values[20] #���l��21�A43�����Ă݂� ossdata[21,] ossdata[43,] #windows�ł̏ꍇ�Aedit(�f�[�^�Z�b�g���j�@�R�}���h�Œ��ځA���邱�Ƃ��\�B edit(ossdata) #�O���t�ɂ̓T���v���ԍ����\�������̂ŁA����ځA�w��ł���Ƃ��낢��֗��B���̂悤�ɂ���1���珇�ɃT���v���ԍ������� #1���珇��1�Â��������������@�V�����ϐ� no�ɓ����B #�\�v�Z�\�t�g�Ȃǂōŏ�����T���v���ԍ���U���Ă����A���̍�Ƃ͕s�v ossdata$no<-c(1:length(ossdata$id)) #�T���v���ԍ�20,21,43�̃f�[�^�����Ă݂� # | �́@�@�_���L���́@or ossdata[ossdata$no== 20 | ossdata$no== 21 | ossdata$no== 43,] |
�}�\ Cook's distance�v���b�g
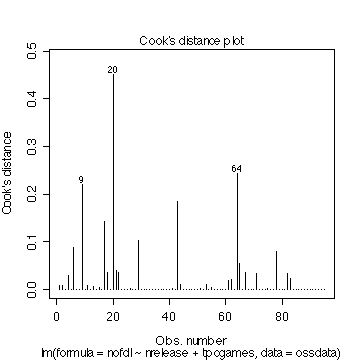
���c�����͂ŁA��肪�������ꍇ�́A���낢��ȑ�
�E�͂���l
�@���̓~�X�̃`�F�b�N
�@���̐����ϐ��̉\���̒lj�
�@�ΐ����Ȃǂ̕ϐ��ϊ�
�@���̃T���v�������O����i�͂���l�_�~�[������j�B
|
#����̃T���v�����͂��������� # �f�[�^�Z�b�g(�I�u�W�F�N�g)�̖��O�̌�� #[-�͂��������I�u�U�x�[�V�����̔ԍ�,] #�̂悤�Ɏw��B #20�Ԗڂ̃I�u�U�x�[�V�������͂��������Ƃ��́A���̂悤�ɁB result2<-lm(nofdl~nrelease+tpcgames,ossdata[-20,]) summary(result2) #�����������ꍇ�́A��x�Ɉ�����͂����Ȃ��̂ŁA�w����J��Ԃ����V�����f�[�^�Z�b�g������B #�@20,21,43�Ԗڂ̃I�u�U�x�[�V�������͂��������Ƃ� #���̃I�u�U�x�[�V�������Ɉُ�l�_�~�[������̂���̎� ossdata$dum20<-matrix(0,length(ossdata$id),1) ossdata$dum20[20]<-1 ossdata$dum21<-matrix(0,length(ossdata$id),1) ossdata$dum21[21]<-1 ossdata$dum43<-matrix(0,length(ossdata$id),1) ossdata$dum43[43]<-1 res2<-lm(nofdl~nrelease+tpcgames+dum20+dum21+dum43,ossdata) summary(res2) |
|
#�\���l�Ǝc���̑��ւ��݂Ă݂� cor(result2$fitted.values,result2$residuals) #�\���l�Ǝc����[��Βl]�̑��ւ��݂Ă݂� cor(result2$fitted.values,abs(result2$residuals)) |
|
#������ϐ��ɂ��Ẵq�X�g�O�����ƃ{�b�N�X�v���b�g hist(ossdata$nofdl) #�����炩�ɐ��K���z�ł͂Ȃ� 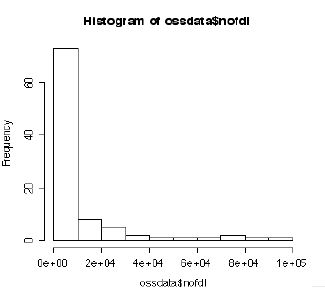 #�{�b�N�X�v���b�g�i���Ђ��}�j boxplot(ossdata$nofdl) # �l�p�������͉������1�A�Q�A�R�l���ʓ_�������B�i��Q�l���ʓ_�͒����l�j #�㉺�ɐL�т�s�������͋t���܂̂s�� # �ɒl=�����l�}(��3�l���� - ��1�l����)*1.5 #�@�ɒl�͈̔͊O�ɂ���T���v���́@�͂���l�@�ƌĂ�� 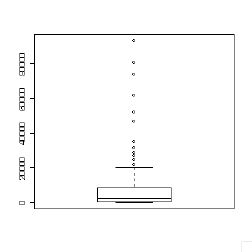
|
|
#���R�ΐ����Ƃ������̂�V�����ϐ� lnofdl �Ƃ��Ē�` #log()�͎��R�ΐ��B�@�@log10()��10��̂Ƃ���ΐ� ossdata$lnofdl<-log10(ossdata$nofdl) hist(ossdata$lnofdl) #�ڂŌ��������͖ڐ���̐���ɂ���Ď�قȂ邪�A���̕ϐ����͐��K���z�ɋ߂��B hist(ossdata$lnofdl,breaks=c(1,2,3,4,5,6)) hist(ossdata$lnofdl,breaks=c(1,1.5,2,2.5,3,3.5,4,4.5,5,5.5,6)) 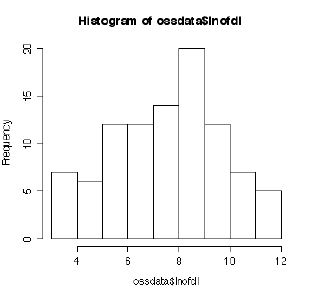 #��ł�Q-Q�v���b�g�������I�ɏo�͂��ꂽ���Aqqnorm()�R�}���h���g���Ζ����I�ɏo�͂����B qqnorm(ossdata$nofdl) 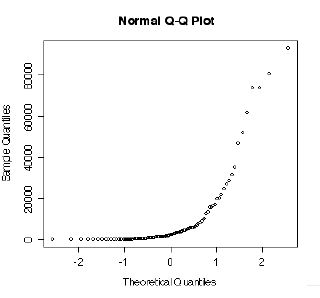
|
|
qqnorm(ossdata$lnofdl) #�ΐ��ϊ��������������ɋ߂��Ȃ��Ă���B 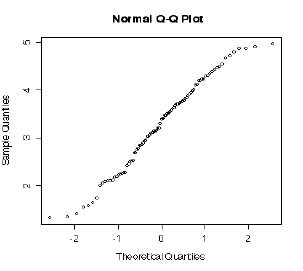 #���Ђ��}���݂Ă��A�͂���l�i�ɒl�̊O�ւ̃v���b�g�j�͂Ȃ��Ȃ����B boxplot(ossdata$lnofdl) 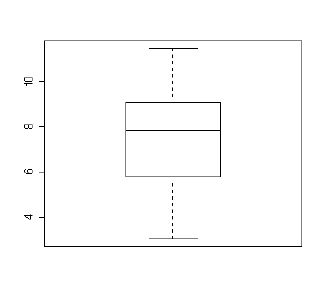 |
|
re2<-lm(lnofdl~nrelease+tpcgames,ossdata) summary(res2) #Coefficients: # Estimate Std. Error t value Pr(>|t|) #(Intercept) 2.860385 0.115268 24.815 < 2e-16 *** #nrelease 0.034430 0.007148 4.817 5.72e-06 *** #tpcgames 0.400312 0.239651 1.670 0.0982 . #--- #Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 #Residual standard error: 0.8268 on 92 degrees of freedom #Multiple R-Squared: 0.2266, Adjusted R-squared: 0.2097 #F-statistic: 13.47 on 2 and 92 DF, p-value: 7.371e-06 plot(res2) 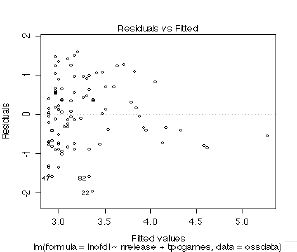 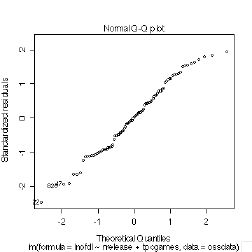
|
|
hist(ossdata$nrelease) boxplot(ossdata$nrelease) #���l�ɑΐ����������̂��`���ĉ�A ossdata$lnrelease<-log10(ossdata$nrelease) res3<-lm(lnofdl~lnrelease+tpcgames,ossdata) summary(res3) #Coefficients: # Estimate Std. Error t value Pr(>|t|) #(Intercept) 2.3556 0.1505 15.657 < 2e-16 *** #lnrelease 1.1364 0.1687 6.735 1.39e-09 *** #tpcgames 0.2986 0.2205 1.354 0.179 #Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 #Residual standard error: 0.7571 on 92 degrees of freedom #Multiple R-Squared: 0.3513, Adjusted R-squared: 0.3372 #F-statistic: 24.92 on 2 and 92 DF, p-value: 2.252e-09 plot(res3) 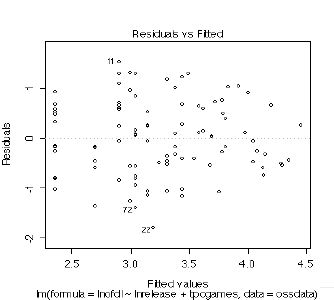 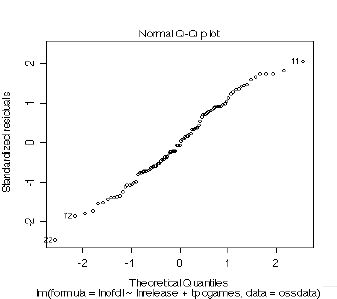
|
�}�\�@���茋�ʂ̂܂Ƃ�
|
�I���W�i���ϐ� |
�]���ϐ��ɂ���log10�ϊ� | �]���ϐ��Ƃ��킹�Đ����ϐ��ɂ��Ă�log10�ϊ� | |
| nrelease | 481.2*** | 0.034430*** | |
| log10(nrelease) | 1.1364*** | ||
| tpcgames | 14158.7*** | 0.400312* | 0.2986 |
| �ؕ� | 3058.4 | 2.860385*** | 2.3556*** |
| R2 | 0.175 | 0.2266 | 0.3513 |
| �C��R2 | 0.1571 | 0.2097 | 0.3372 |
log (y) =��log(x) + ��0
(dy/y)/(dx/x) =(dy/dx)*(x/y) =(�� x��-1e��0) x/ (x�� * e��0 )=��
���j�ΐ��̒��10�ł�e�ł����ʂ͓����B
(2)����^���ւ̑Ή�
�@��L�̕ϐ��ϊ��őΉ��\�ȏꍇ������B
�@����^���f�������Ă͂߂������悢�ꍇ������B�ڂ����͏ȗ��B
�@�@��@�@y= ��1�w�@+�@��2�w2�@+�@��3�w3
(3)���d������
�@��A���͂̑O��F�����ϐ������^�Ɨ��B
�E���̉��肪��������Ă��Ȃ��Ƃ��̏Ǐ�F�s����Ȑ��茋��
�@�T���v���������������ƁA���茋�ʂ��傫���ω��B
�@�ϐ�����������������肷��ƁA���茋�ʂ��傫���ω��B
�@�����I�Ɍ��Ă������ȕ���
�@�L�ӂɂȂ肻���ȕϐ����L�ӂƂȂ�Ȃ��i�W���덷���傫���At�l���������j�B
�E���̓�ɒ��ӂ���K�v������B
�@�@(a)�����ϐ��Ԃɍ������ւ��Ȃ����H
�@�@(b)�����ϐ��Ƒ��̐����ϐ��̐��h�a�Ƃ̊Ԃɍ������ւ��Ȃ����H
�@�O�҂ɂ��Ă͕ϐ��Ԃł̑��ւ��݂�킩��B��҂ɂ��Ă͑��ւ��݂邾���ł͂킩��Ȃ����Ƃ������B
�@��P�@�_�~�[�ϐ��̒�`���������Ă���ꍇ�ɂ�(b)��������B
�@�@�@��@���ʃ_�~�[����`�����ꍇ
dmale,
dfemale
�@�ɂ��ẮA���L�̊W������B
dmale+dfemale=1
�@�@�܂�
�@�@�@dmale=1-dfemale
�@������̕ϐ�������ϐ��Ƃ��Ďg�����Ƃ͕s�K�B
�@�@��Q�@�J���i�K�_�~�[�����ׂē���Ă��܂����Ƃ��B
�@�K���ɂ��AR����͖�肪���邱�Ƃ������Ă����B
|
ossdata$devst2<-matrix(0,length(ossdata$devstage),1) ossdata$devst2[ossdata$devstage==2]<-1 ossdata$devst3<-matrix(0,length(ossdata$devstage),1) ossdata$devst3[ossdata$devstage==3]<-1 ossdata$devst4<-matrix(0,length(ossdata$devstage),1) ossdata$devst4[ossdata$devstage==4]<-1 ossdata$devst5<-matrix(0,length(ossdata$devstage),1) ossdata$devst5[ossdata$devstage==5]<-1 ossdata$devst6<-matrix(0,length(ossdata$devstage),1) ossdata$devst6[ossdata$devstage==6]<-1 res<-lm(nofdl~nrelease+devst2+devst3+devst4+devst5,ossdata) summary(res) #Coefficients: # Estimate Std. Error t value Pr(>|t|) #(Intercept) 25735.9 8870.3 2.901 0.00468 ** #nrelease 465.2 158.1 2.943 0.00414 ** #devst2 -26367.0 10723.3 -2.459 0.01587 * #devst3 -24740.9 9776.9 -2.531 0.01315 * #devst4 -23568.0 9382.2 -2.512 0.01381 * #devst5 -17737.0 9103.1 -1.948 0.05451 . #��`�������ׂĂ����Đ��� res2<-lm(nofdl~nrelease+devst2+devst3+devst4+devst5+devst6,ossdata) summary(res2) #Coefficients: (1 not defined because of singularities) #�@�ϐ��̈�́A�����ϐ��Ԃ̋����U�s�@���ف@�ł��������ߗp�����Ȃ������Ƃ������b�Z�[�W # Estimate Std. Error t value Pr(>|t|) #(Intercept) 25735.9 8870.3 2.901 0.00468 ** #nrelease 465.2 158.1 2.943 0.00414 ** #devst2 -26367.0 10723.3 -2.459 0.01587 * #devst3 -24740.9 9776.9 -2.531 0.01315 * #devst4 -23568.0 9382.2 -2.512 0.01381 * #devst5 -17737.0 9103.1 -1.948 0.05451 . |
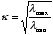
�@���Ƃ̐����ϐ��̊ԂɊ��S�Ȓ����W������ꍇ�A���֍s��̍ŏ��̌ŗL�l��0�ƂȂ�Ƃ�������������B����ăȂ̒l���傫���قǁA���d�������̋��ꂪ���邱�Ƃ��Ӗ�����B
�@��̎����A��>1�����o���I�ɁA�������Ȃ�15���z���Ă���Ƃ��ɂ́A���d������������Ƃ����B30���z����悤�ȏꍇ�ɂ́A����l���������悢�B
|
#���֍s����v�Z���邽�ߐV�����ʂ̃f�[�^�Z�b�g�ɁB a<-data.frame(ossdata$nrelease,ossdata$devst2,ossdata$devst3,ossdata$devst4,ossdata$devst5,ossdata$devst6) #���֍s��쐬 cr<-cor(a) cr #�ϐ��Ԃ̑��ցB���ɍ������ւ݂͂��Ȃ��B #���ꂾ���ł͐��^�Ɨ����ۂ��͂킩��ɂ����B�B # ossdata.nrelease ossdata.devst2 ossdata.devst3 ossdata.devst4 #ossdata.nrelease 1.00000000 -0.17250438 -0.2039430 0.2126873 #ossdata.devst2 -0.17250438 1.00000000 -0.1364683 -0.1812201 #ossdata.devst3 -0.20394303 -0.13646831 1.0000000 -0.2689474 #ossdata.devst4 0.21268731 -0.18122009 -0.2689474 1.0000000 #ossdata.devst5 0.05449983 -0.26994300 -0.4006205 -0.5319952 #ossdata.devst6 0.01745612 -0.06357621 -0.0943530 -0.1252940 # ossdata.devst5 ossdata.devst6 #ossdata.nrelease 0.05449983 0.01745612 #ossdata.devst2 -0.26994300 -0.06357621 #ossdata.devst3 -0.40062049 -0.09435301 #ossdata.devst4 -0.53199518 -0.12529400 #ossdata.devst5 1.00000000 -0.18663625 #ossdata.devst6 -0.18663625 1.00000000 #�ŗL�l�̌v�Z #eigen(�s��̓����Ă���f�[�^�Z�b�g��) #�ŌŗL�l���v�Z���Ă���� ev<-eigen(cr) ev #�ŗL�l 6�ϐ��Ȃ̂łU�v�Z�����B�@�@10-16��0�ɋɂ߂ċ߂����̂�����B #$values #[1] 1.567999e+00 1.490406e+00 1.132193e+00 1.060070e+00 7.493321e-01 #[6] -8.881784e-16 #�ŗL�x�N�g���@i��߂́A���i�Ԗڂ̌ŗL�l�ɑΉ�����B����Ɂ}���������̓�����݂���B #$vectors # [,1] [,2] [,3] [,4] [,5] [,6] #[1,] 0.03312105 0.57092965 -0.11965781 -0.09368358 0.80613133 3.249924e-16 #[2,] 0.11076594 -0.32023099 0.79640835 0.12134588 0.35456416 -3.323796e-01 #[3,] 0.21884350 -0.55453819 -0.58758651 0.07454660 0.30519649 -4.479229e-01 #[4,] 0.57964685 0.48072747 0.01321388 0.19994914 -0.33908493 -5.270463e-01 #[5,] -0.77242101 0.17989474 -0.04083312 0.08725759 -0.09159208 -5.944185e-01 #[6,] 0.07820965 -0.02275568 0.06569541 -0.96090989 -0.08901652 -2.403701e-01 #������=sqrt(�ő�̌ŗL�l/�ŏ��̌ŗL�l�j #�ŗL�l��ev$values�ɓ����Ă���̂Ŏ��̂悤�Ɍv�Z ra<-sqrt(abs(max(ev$values)/min(ev$values))) ra #[1] 42016787 #15�����傫���̂ő��d������������B��������̑K�v�B |
|
#devst2�������Ă݂� #���֍s����v�Z���邽�ߐV�����ʂ̃f�[�^�Z�b�g�ɁB b<-data.frame(ossdata$nrelease,ossdata$devst3,ossdata$devst4,ossdata$devst5,ossdata$devst6) #���֍s��쐬 cr2<-cor(b) cr2 ev2<-eigen(cr2) ev2 #$values #[1] 1.5640608 1.4443809 1.0617505 0.8103489 0.1194589 ra2<-sqrt(abs(max(ev2$values)/min(ev2$values))) ra2 #[1] 3.618408 #�������Ȃ�15�����������Ȃ����B |
|
res2<-lm(nofdl~nrelease+devst3:nrelease+devst4:nrelease+devst5:nrelease+devst6:nrelease,ossdata) summary(res2) #Coefficients: # Estimate Std. Error t value Pr(>|t|) #(Intercept) 4664.6 2501.4 1.865 0.0655 . #nrelease -781.5 1632.0 -0.479 0.6332 #nrelease:devst3 810.8 1704.4 0.476 0.6354 #nrelease:devst4 1122.1 1616.2 0.694 0.4893 #nrelease:devst5 1394.3 1606.1 0.868 0.3877 #nrelease:devst6 3594.8 1711.9 2.100 0.0386 * #--- #Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1 #Residual standard error: 16860 on 89 degrees of freedom #Multiple R-Squared: 0.2359, Adjusted R-squared: 0.193 #F-statistic: 5.497 on 5 and 89 DF, p-value: 0.0001865 plot(res2) #devst3��nrelease�Ƃ̐� ossdata$dev3nrel<-ossdata$devst3*ossdata$nrelease ossdata$dev4nrel<-ossdata$devst4*ossdata$nrelease ossdata$dev5nrel<-ossdata$devst5*ossdata$nrelease ossdata$dev6nrel<-ossdata$devst6*ossdata$nrelease #���֍s����v�Z���邽�ߐV�����ʂ̃f�[�^�Z�b�g�ɁB a<-data.frame(ossdata$nrelease,ossdata$dev3nrel,ossdata$dev4nrel,ossdata$dev5nrel,ossdata$dev6nrel) #���֍s��쐬 cr<-cor(a) cr |
| t()�@�@�@�s��i�x�N�g���j��]�u����i�s�Ɨ�����ւ���j�B |
|
��1 ev$vector # [,1] [,2] [,3] [,4] [,5] [,6] #[1,] 0.03312105 0.57092965 -0.11965781 -0.09368358 0.80613133 3.249924e-16 #[2,] 0.11076594 -0.32023099 0.79640835 0.12134588 0.35456416 -3.323796e-01 #[3,] 0.21884350 -0.55453819 -0.58758651 0.07454660 0.30519649 -4.479229e-01 #[4,] 0.57964685 0.48072747 0.01321388 0.19994914 -0.33908493 -5.270463e-01 #[5,] -0.77242101 0.17989474 -0.04083312 0.08725759 -0.09159208 -5.944185e-01 #[6,] 0.07820965 -0.02275568 0.06569541 -0.96090989 -0.08901652 -2.403701e-01 t(ev$vector) # [,1] [,2] [,3] [,4] [,5] [,6] #[1,] 3.312105e-02 0.1107659 0.2188435 0.57964685 -0.77242101 0.07820965 #[2,] 5.709297e-01 -0.3202310 -0.5545382 0.48072747 0.17989474 -0.02275568 #[3,] -1.196578e-01 0.7964084 -0.5875865 0.01321388 -0.04083312 0.06569541 #[4,] -9.368358e-02 0.1213459 0.0745466 0.19994914 0.08725759 -0.96090989 #[5,] 8.061313e-01 0.3545642 0.3051965 -0.33908493 -0.09159208 -0.08901652 #[6,] 3.249924e-16 -0.3323796 -0.4479229 -0.52704628 -0.59441848 -0.24037009 |
| �x�N�g��1 %*% �x�N�g��2�@�x�N�g��1��2�̓��ς��v�Z����B |
|
�� 1�Ԗڂ̌ŗL�x�N�g����2�Ԗڂ̌ŗL�x�N�g���̓��� t(ev$vector[,1]) %*% ev$vector[,2] # [,1] #[1,] -1.978100e-18 �� 1�Ԗڂ̌ŗL�x�N�g����3�Ԗڂ̌ŗL�x�N�g���̓��� t(ev$vector[,1]) %*% ev$vector[,3] # [,1] #[1,] 1.521965e-16 #���ς�0�Ƃ������Ƃ́A�ӂ��̃x�N�g���������i���ւ�0�j�Ƃ������ƁB |
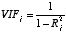
�@������Ri2��xi�������ϐ��A����ȊO�̂��ׂĂ̐����ϐ�������ϐ��Ƃ����Ƃ���R2�B
�@�ϐ�xi�����̐����ϐ��ɂ���Ċ��S�ɐ�������Ă���Ƃ���Ri2=1�ƂȂ�B
�@VIF ���傫���ϐ��قǑ��̕ϐ��i�̐��`�����j�Ƃ̑��ւ��������Ƃ��Ӗ�����B
|
#�e�����ϐ��ɂ��āA���̐����ϐ��Ő�������B r<-lm(nrelease~dev3nrel+dev4nrel+dev5nrel+dev6nrel,ossdata) summary(r) r<-lm(dev3nrel~nrelease+dev4nrel+dev5nrel+dev6nrel,ossdata) summary(r) r<-lm(dev4nrel~nrelease+dev3nrel+dev5nrel+dev6nrel,ossdata) summary(r) r<-lm(dev5nrel~nrelease+dev3nrel+dev4nrel+dev6nrel,ossdata) summary(r) r<-lm(dev6nrel~nrelease+dev3nrel+dev4nrel+dev5nrel,ossdata) summary(r) #VIF=1/(1-R2)���v�Z����܂ł��Ȃ��AR2���ɂ߂đ傫���B |
A ei=��iei